Scaling AI First Collaboration Across the Organization
By Derek Neighbors on August 12, 2025
Teams get one local win with AI, then the rollout flatlines. Tools spread; outcomes don’t. You scale by standardizing modes, evaluation, and iteration, not by multiplying licenses. This requires the mindset shift that treats AI as a collaborator, not a feature.
The Scaling Problem
The moment one team starts winning with AI, the organization does the predictable thing: multiply the tools. Licenses go up. Results don’t. Because you can’t scale what you don’t understand.
What scales isn’t the tool. It’s the decisions, the evaluation criteria, and the iteration systems that produced the result. Copy those, and capability compounds. Copy prompts, and you get noise dressed up as progress.
Hard truth: copying “how we used AI” is useless without copying “who leads when,” “what success looks like,” and “how we iterate.”
I watched a team do this the wrong way. They gave out LLM licenses across Sales and Support, copied a few prompts, and called it a rollout. First month: no movement on time‑to‑first‑touch or CSAT. When we wrote the mode map and the accept/reject rubric, cycle time dropped and quality went up. The tools didn’t change. The standards did.
Excellence scales by standards, not tools. Craft is discipline made visible, and excellence is rented, not owned. If you can’t name the rules, you can’t transmit the craft.
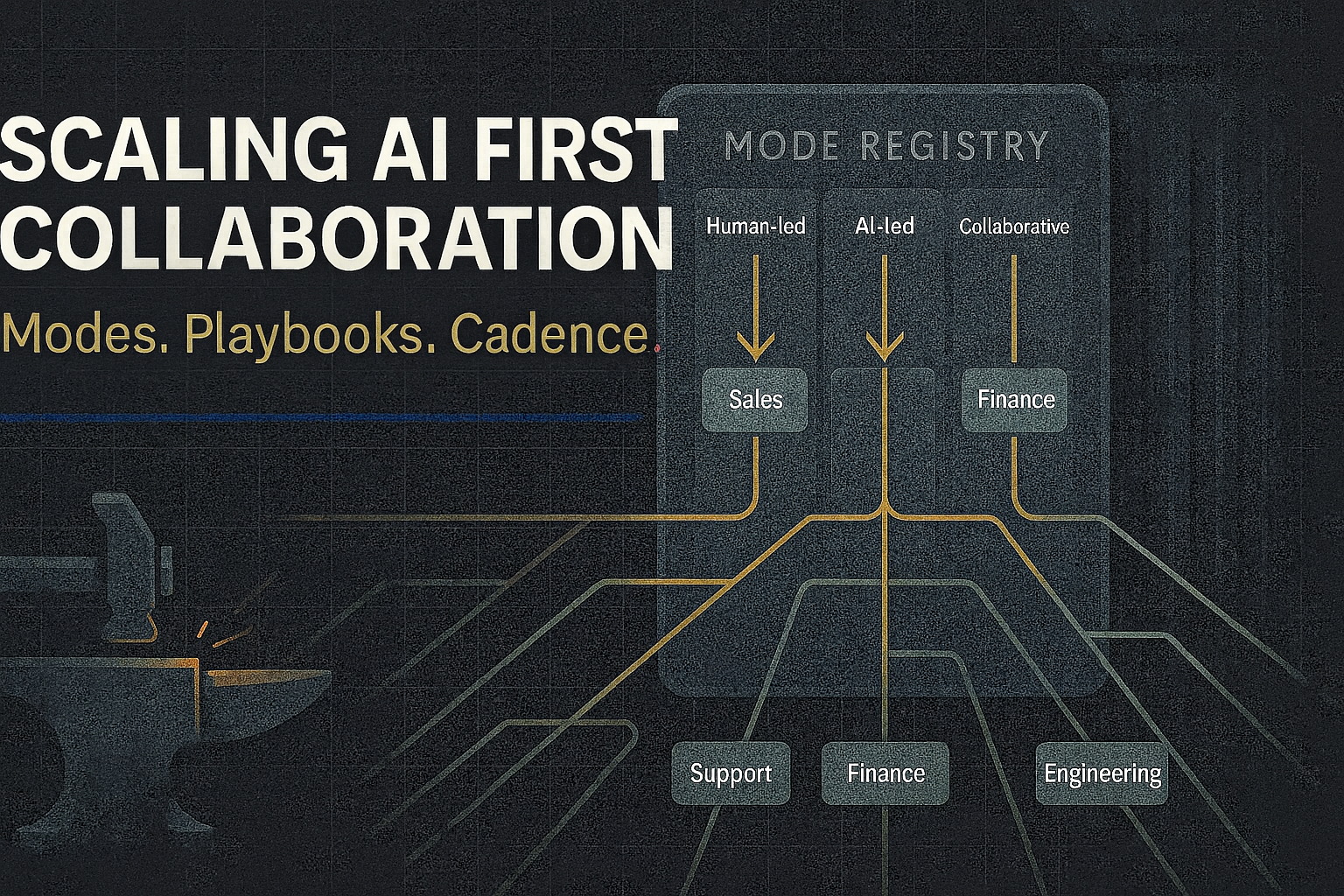
Clear Rules for Who Leads When (Org-Level Discipline)
The human problem: leaders cling to control, teams hide behind busywork, and everyone avoids being exposed. If you’re scaling AI to look innovative, you’re already failing. Name who leads, name the one number, and face the results.
You don’t scale work until you standardize modes. Every step in a workflow is declared human-led, AI-led, or collaborative, by rule. This is phronesis in practice: practical wisdom about who should lead when, and why.
- Human-led: human decides; AI supports. Strategic calls, ethics reviews, brand/taste decisions.
- AI-led: AI decides by rule; humans review exceptions. Lead routing by fit/intent. Anomaly triage.
- Collaborative: AI drafts → human edits → AI executes. Support replies. Research summaries. Code refactors under constraints.
Entry and exit criteria must be explicit. When do we promote a step from collaborative to AI-led? When the evaluation rubric hits a threshold for accuracy and risk. When do we demote? When exceptions exceed the cap.
Make the registry visible. Each team publishes its mode map for critical workflows. Silent mode drift is how standards die.
Playbooks, Not Docs (Plans That Actually Run)
A winning workflow becomes a plan another team can actually run:
- One number to move in 14–30 days (primary KPI)
- Mode map: who leads when
- Inputs/outputs and quality criteria
- Evaluation rubric (accept/reject thresholds)
- Iteration loop and “when to scale” rule
Minimum bar: another team can run it in under one hour of setup. If they need a meeting to understand it, it’s not a playbook. It’s a memo.
Example: Support Reply Playbook (Collaborative Mode)
- KPI: first-response time to < 15 minutes with CSAT ≥ 4.6
- Inputs: ticket text, customer profile, policy constraints
- Rubric: tone, accuracy, policy adherence; threshold ≥ 90% on calibration set
- Loop: generate 3 drafts → human edits → AI sends → measure → refine prompts/rubric weekly
- Scale rule: sustain targets 2 cycles → publish versioned playbook to registry
Function Rollouts That Travel
Sales
- AI-led inbound routing by fit/intent; humans review edge cases
- KPI: time-to-first-touch, win rate delta on playbook-run deals
- Collaborative proposal drafting with human-led pricing/terms; KPI: cycle time to proposal, close rate
Support
- Collaborative reply drafting; KPI: first-response time, CSAT; exception rules for sensitive domains
- AI-led suggested resolutions with human approval; KPI: resolution time, reopen rate
Finance
- Human-led decisions; AI-led variance prep and scenario trees; KPI: month-end close time, forecast accuracy
- Collaborative vendor analysis packets; KPI: savings identified vs realized
Engineering/Product
- Collaborative: AI drafts tests/refactors; human reviews design; KPI: lead time for changes, deployment frequency, change failure rate
- AI-led CI checks; if thresholds fail, demote to human-led review until standards recover
Cadence and Handoffs (Operating Rhythm)
Run four-week rollout cycles per function:
- Week 1: Pick the workflow; set one KPI; publish the mode map
- Week 2: Run the Outcome Engine and capture the evaluation rubric
- Week 3: Iterate and harden the playbook (package for reuse)
- Week 4: Scale to the next team; record deltas; submit to registry
Ownership: each playbook has a single Owner; the org has a Curator for the registry. Handoffs between teams define inputs/outputs, SLA, failure responses, and fallback mode.
Measurement That Bites
A handful of metrics prove scale. Everything else is noise.
- Sales: time-to-first-touch; win rate delta on playbook-run opportunities
- Support: first-response time; CSAT/NPS; resolution time; reopen rate
- Finance: close cycle time; forecast error; variance review throughput
- Eng/Product: DORA (lead time, deploy frequency, change failure rate, MTTR)
- Process: playbooks published; playbooks adopted; cycles completed; exception ratio trend
If a playbook doesn’t move its one number, it doesn’t scale, no matter how impressive the demo.
Failure Modes (And How to Keep the Forge Hot)
I watched a VP throw $100K at more AI licenses because admitting “we lack standards” felt like weakness. This is the trust erosion pattern that hollows out organizations from the inside. It wasn’t tools. It was courage. Once we wrote three rules for who leads when, picked one number, and published deltas, everything moved.
- Teams sneak back to human-only because accountability is uncomfortable. Fix: required attestation in tooling or automated checks.
- Vanity dashboards glow while outcomes stall. Fix: enforce a single primary KPI and publish deltas.
- Knowledge gets trapped in documents no one can use. Fix: publish plans another team can actually run, with examples and checklists.
- Everything becomes an exception. Why it kills scale: exceptions quietly break trust in the standard, turn every case into a special case, and dissolve shared discipline. Fix: cap exception ratios; if exceeded, revert to collaborative mode and refine the rubric until the rule holds again.
Implementation Pattern (From One Team to Many)
Repeat this pattern across the org:
- Week 1: Pick one collaboration and map modes
- Week 2: Write the rules (who leads when) and the evaluation rubric
- Week 3: Build the workflow around Generate → Evaluate → Iterate → Scale → Learn
- Week 4: Install the Feedback Forge and publish the playbook
Do it in Sales first? Fine. Just don’t mistake early wins for scale. Scale happens when other teams run your playbook and hit your numbers.
Final Thoughts
Scaling AI First isn’t headcount or tool count. It’s disciplined replication of what actually works, guided by principles over process.
You don’t need more AI. You need fewer, better playbooks, mode‑disciplined, metrics‑honest, and ruthlessly iterated. Build the registry, package the wins, install the cadence, and let capability compound.
If every AI tool vanished tomorrow, this would still work because standards, clear roles, and honest measurement are what scale excellence.
Clear standards don’t just scale output; they free your team to focus on the work only humans can do. That’s arete in practice.
This week’s challenge:
- Publish one runnable playbook with a single primary KPI and a clear mode map
- Have a second team run it with under one hour of setup
- Compare the deltas; if exceptions exceed your cap, demote the step and fix the rubric before scaling
Sustainment requires culture: discipline to keep the rules, candor to publish real deltas, and courage to measure what bites. That discipline is the gateway to everything that follows. Culture change is next. Today, prove you can scale a result.
Courage is the leadership test here: the courage to let go of control, to publish the numbers even when they embarrass you, and to hold the line when exceptions pile up. Without discipline, candor, and courage, this collapses into theater.
Want help installing the cadence and accountability? MasteryLab is where we practice arete in the real world AI‑enhanced reflection, daily arete audits, peer accountability, and challenges that turn ideas into behavior across character, competence, courage, and community.




